LLMProbe: Early-2026 Automated Scanning of Public LLM Inference Endpoints
Summary
On January 8, 2026, our systems observed a coordinated campaign of automated HTTP requests targeting common Large Language Model (LLM) API endpoints such as /v1/chat, /v1/chat/completions, /openai/v1/chat/completions, and /api/chat. The attacker iterated through multiple popular model names (gpt-4o, llama3, grok-2, mistral-large-latest, etc.) and sent the same probing prompt in each request in order to fingerprint the endpoint and determine whether inference was available without authentication or metering.
These requests have been classified as LLMProbe Request Attempts and represent a growing trend in automated model fingerprinting and open inference abuse. This post details the observed behavior, assesses attacker motivations, and provides defensive guidance.
Timeline of the Early-2026 LLM Probing Campaign
The campaign began unexpectedly in the first days of January 2026 with short bursts of automated probing activity against public-facing LLM inference endpoints. Initially, the volume was low and sporadic, consistent with reconnaissance-level enumeration. Within hours, the attackers escalated into a more sustained pattern, distributing requests across multiple API paths and model names in an attempt to identify unauthenticated inference surfaces.
The timeline below captures this initial probing phase, showing the emergence, escalation, and stabilization period of the campaign over a multi-day window:

Observed Activity
We recorded a high-volume sequence of HTTP POST requests directed at servers running exposed ports on TCP/8080. A representative request looked like:



Across hundreds of requests, the attacker:
- varied the endpoint path
- varied the model name
- reused the same prompt
- expected an inference response
These are strong indicators of automated API surface exploration rather than legitimate client usage.
Attacker Objective
Unlike classical RCE or SQL injection campaigns, this campaign was not attempting to break into a backend or exfiltrate data directly. Instead, the attacker appears to be focused on identifying LLM endpoints that allow unauthenticated inference.
The goals of such scans typically include:
1. Open Inference Discovery
Identify models that can be queried without:
- API keys
- authentication
- rate limits
- billing
This enables resource parasitism, where a botnet uses someone else’s inference infrastructure as computational fuel.
2. Model Fingerprinting
Determine what model is deployed behind the endpoint. This allows attackers to classify servers by:
- model vendor & family
- capability & alignment
- safety constraints
- system time access
- streaming capability
- output token limits
3. Infrastructure Mapping for Later Abuse
Endpoints passing inference tests may be added to botnet inference pools used for:
- spam & scam content generation
- SEO abuse
- phishing campaigns
- bulk rewriting / paraphrasing
- synthetic persona automation
This behavior is consistent with the emerging underground marketplace referred to as “Baithive”, where discovered inference nodes are traded similarly to how open SMTP relays were traded a decade ago.
Why This Prompt?
The probing prompt:
“How many states are there in the United States? What is today’s date? What model are you?”
is intentionally harmless, but maximally revealing.
| Prompt | Purpose |
|---|---|
| How many states… | Tests factual baseline |
| What is today’s date? | Tests clock/system context |
| What model are you? | Tests self-identification |
It allows automated classification without triggering content filters and without generating analyst suspicion at first glance.
Methodology
The campaign exhibited several consistent traits:
1. Multi-endpoint Probing
The attacker tested canonical LLM vendor paths:

This suggests a vendor-agnostic scanner aware of OpenAI, Anthropic, Mistral, Groq, and Meta API patterns.
2. Vendor Model Enumeration
We observed a rotating set of model names including:
gpt-4ollama3llama-3.3-70b-versatilegrok-2mistral-large-latestcommand-r-plusdeepseek-chat

Some may not exist on the target; the attacker is probing the model selector surface, not necessarily expecting accuracy.
3. Automation Indicators
User agent:
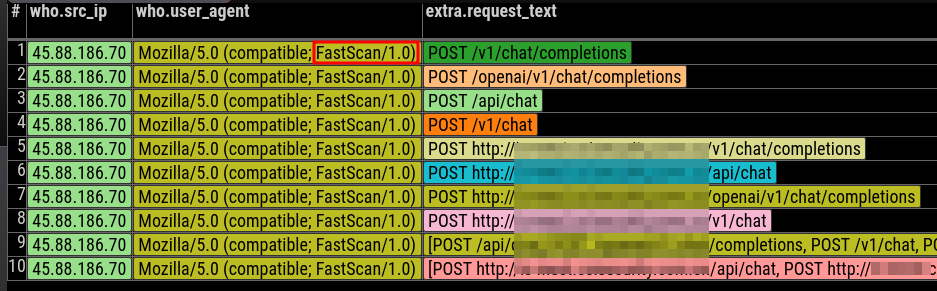
resembles RapidScan patterns used in cloud and IoT botnets.
Conclusion
The LLMProbe campaign demonstrates an emerging class of attacks where LLM inference itself becomes the resource to steal, much like compute cycles in the cryptojacking era.
LLM service operators should recognize that:
– inference is billable, valuable, and abusable.
As LLM workloads shift to persistent infrastructure (GPUs, inference clusters, edge models), unattended inference endpoints will continue to be targeted for unauthorized compute extraction, content abuse, and model fingerprinting.
We strongly recommend applying authentication and rate limiting before deploying LLM services publicly.




